
Some of the questions you should answer :
- Is the graph database actually the right fit for my application ?
- Is this investment future-proof ?
- What is the cost of ownership for each of the graph databases you would like to choose ?
What is a graph database ?
Graph databases are optimised to store and query the relationships between data items.
Remember these 2 main points :
- The data items are stored as vertices of the graph.
- The relationships are stored as edges of the graph.
Each edge has a type and direction. It is directed from one vertex (start) to another vertex (end). Vertices are sometimes also referred to as nodes. And edges are sometimes referred to as predicates.
Let’s consider a relationship like depicted in the below diagram :
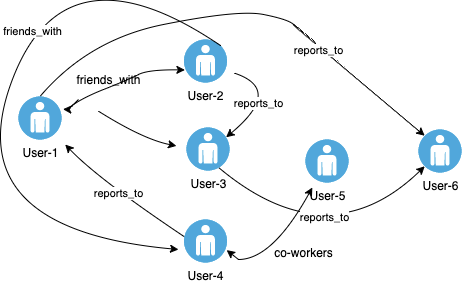
The edges are shown as named arrows, and the vertices represent specific people and relationships that they connect. A simple traversal of this graph can tell you who user-1’s friends are.
Why graph databases ?
A graph database is an optimised database to store highly connected dataset. When the relationships between entities are at the core of data that you are trying to model, graph databases are a natural choice.
A graph database can query relationships between billions of vertices without bogging down.
Use cases of a graph database ?
- Gremlin – is a graph traversal language of Apache TinkerPop. Gremlin is a functional, data-flow language that enables users to succinctly express complex traversals on (or queries of) their application’s property graph
- SPARQL – is an RDF query language—that is, a semantic query language for databases—able to retrieve and manipulate data stored in Resource Description Framework (RDF) format
- Cypher – Cypher is Neo4j’s graph query language that allows users to store and retrieve data from the graph database. Neo4j wanted to make querying graph data easy to learn, understand, and use for everyone, but also incorporate the power and functionality of other standard data access languages
Amazon neptune
Amazon neptune is a managed graph database service. It is used as a webservice and is a part of Amazon Web Services. Amazon Neptune supports popular graph models property graph and W3C‘s RDF, and their respective query languages Apache TinkerPop Gremlin[2] and SPARQL,[3] including other Amazon Web Services products. Users can run, build and run their applications with highly connected data sets. It is mainly built with a purpose to provide a high-performance graph database engine. Neptune is fully managed, so you no longer need to worry about database management tasks like hardware provisioning, software patching, setup, configuration, or backups.
AWS Neptune Visualization is not built in natively. However, data can be visualized with Amazon SageMaker Jupyter notebooks, or third-party options like Metaphactory, Tom Sawyer Software, Cambridge Intelligence/Keylines, and Arcade.
Amazon Neptune is advertised by AWS as
“A fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. The core of Neptune is a purpose-built, high-performance graph database engine that is optimized for storing billions of relationships and querying the graph with milliseconds latency. Neptune supports the popular graph query languages Apache TinkerPop Gremlin and W3C’s SPARQL, allowing you to build queries that efficiently navigate highly connected datasets. Neptune powers graph use cases such as recommendation engines, fraud detection, knowledge graphs, drug discovery, and network security.”
Neo4j
Neo4j is also a graph database. Unlike Amazon’s neptune , neo4j is open source. It uses cypher language. It comes with a graph visualisation which becomes necessary when working with a highly connected data.
It is “ The world’s leading graph database”
Points of Comparison
- Classification
- Amazon Neptune is classified as a “graph database as a service”. It is a fast reliable database built for the cloud. fully-managed cloud-based high-performance graph database that is available on AWS.
- Neo4j is classified as the world’s leading native graph database platform.
- Database Model
- Amazon Neptune is based on Graph DBMS and RDF stores.
- Neo4j is based on the Graph DBMS database model.
- DB-engines Ranking
- Neo4j holds the 18th ranking in Db engines as of March 2021 :
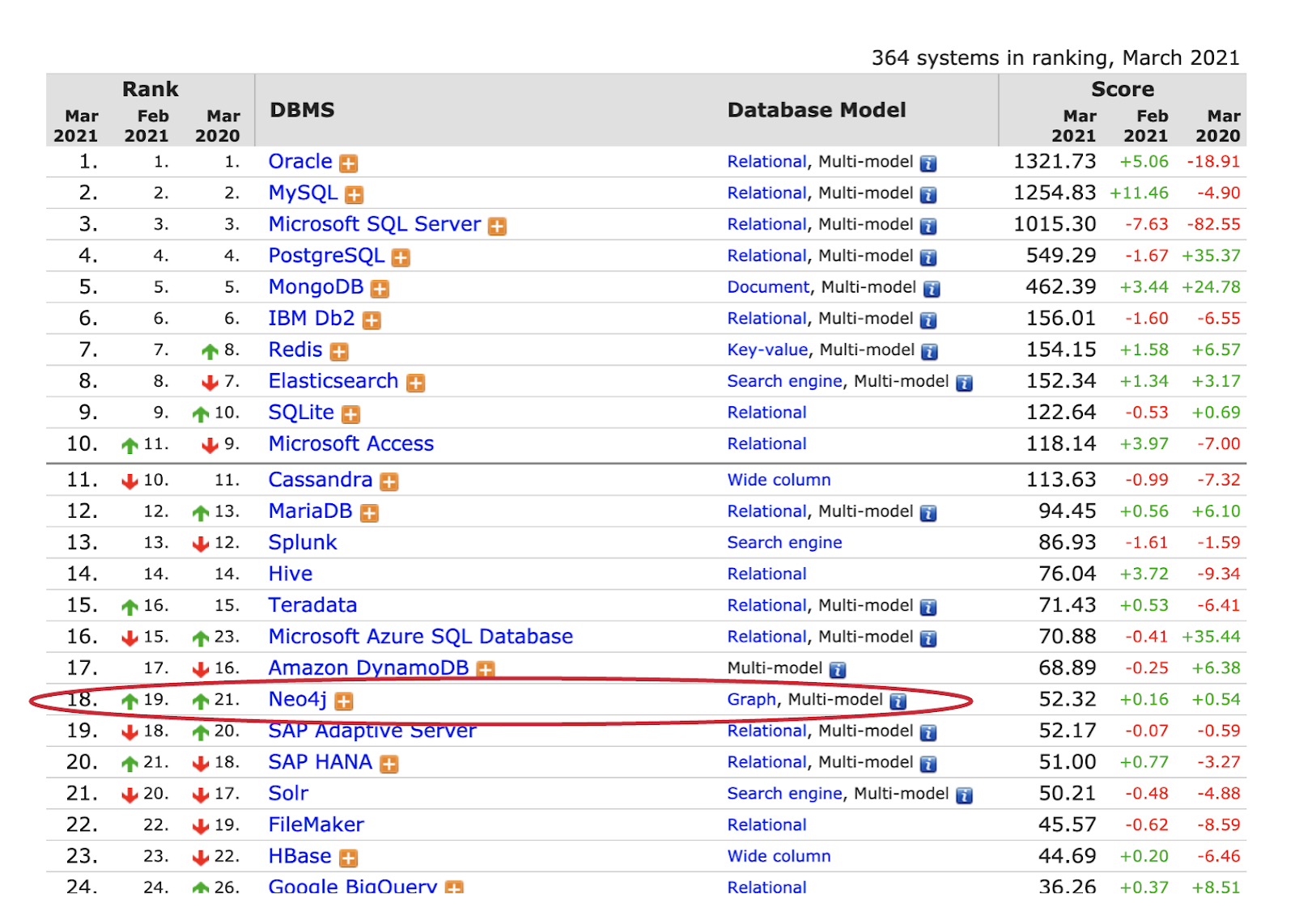
- Though neo4j’s DB engine is ranked 18th, its 18th among well baked engines like Oracle, MySQL, ElasticSearch and so on. Also, its ranked no 1 among all the graph database engines.

- Query Language
- In Amazon Neptune you can build graph models using query languages: Apache TinkerPop Gremlin and SPARQL.
- Whereas in Neo4j, is written in java and scala and is accessible using the well known query language Cypher. The cypher syntax is a great way to communicate between conceptual to technical possibly making it easier for people to understand what is going within the graph itself.
- Language Support
- Amazon Neptune supports C#, Go, Java, JavaScript, PHP, Python, Ruby, Scala.
- Neo4j supports a wide range of programming languages including: .Net, Clojure, Elixir, Go, Groovy, Haskell, Java, JavaScript, Perl, PHP, Python, Ruby, and Scala.
- Server Operating System
- Amazon Neptune – hosted by AWS.
- Neo4j – The server operating systems are Linux, OS X, Solaris, and Windows.
- Pricing
- AWS pricing for Amazon neptune :
- On-Demand instance pricing : you will need to pay for the compute instances needed for read-write workloads as well as Amazon Neptune replicas.
- Database Storage & I/Os : Storage is billed in per GB-month increments and I/Os are billed in per million request increments.
- Backup storage : you are charged for the storage associated with your automated database backups and database cluster snapshots.
- Data transfer : you are charged per GB for data transferred in and out of AWS Neptune.
- Neo4j is open source. This means –
- You may -Rely on Database as a service providers like Graphene, xenonstack – when you want a out of the box offering.
- Or deploy it yourself. But in this case you will have to manage the uptime, reliability and the backups yourself.
- AWS pricing for Amazon neptune :
- Visualisation
- Amazon Neptune lacks graph data visualisation. However visualisation can be achieved using Amazon SageMaker Jupyter notebooks, But however this comes with an extra cost like most of the pricing format for AWS services.
- Whereas Neo4j comes with a powerful, customisable graph visualisation browser tool. The Neo4j browser is based on the built-in D3.js library. On top of being an easy way to visualize graph data, it can be used for querying, adding data and creating relationships amongst other things. Queries run in the Neo4j Browser are rendered either as in a visual graph, in a table format or an ASCII-table result.
- High- Availability and Replication
- Amazon Neptune
- The data here is divided into 10 GB “chunks” and spread across many disks. Each chunk is replicated six ways across three availability zones. Loss of upto two copies does not affect writes, while loss of upto three copies will affect reads.
- It supports upto 15 read replicas, replicated asynchronously with automated failovers. The replica instances share similar storage as the primary instance.
- It is possible to modify and prioritise certain replicas as failover targets by assigning promotion priority.
- In order to increase availability, you can increase replicas, Amazon neptune is vertically scalable instead of being horizontally scalable. There is no sharding.
- Neo4j
- Instances have master-slave cluster replication in high-availability mode. A master maintains a master copy of each data object and replicates this to each slave. The full data set is replicated across the entire cluster.
- The updates are made from the master which has no regard to the number of instances that fail, as long as it remains available.
- It does not have master-master replication and there is no way to set master priority for instances
- Even Though writes are synced with the master, reads can be done locally on each slave. Hence increasing the read capacity linearly with instances.
- Neo4j supports in-memory sharding of the graph along the chunks on specific instances. Queries that map to those chunks can be routed.
- Amazon Neptune
- ACID transactions
- Amazon Neptune provides an ACID transactional model like Aurora and DynamoDB. A write master of transactions is committed on the replicas. However there is an exception for bulk upload features that might suspend ACID to enable higher write throughput rates.
- Neo4j uses ACID – all operations in a transaction succeed and are able to commit tens of thousand transactions per second.
- Security
- Amazon Neptune isolates your Graph Data in Virtual Private Clouds or encrypted IPsec VPNs on-premises. There are also firewall settings and network access controls to database instances.
- Permission are managed with standard AWS IAM roles.
- Neo4j Native user role management is only available with Neo4j Enterprise Edition.
- Cloud
- With Amazon Neptune, you will need to purchase the cloud AWS. Even though the query language, Apache TinkerPop Gremlin or W3C SPARQL are not vendor specific, the DB engine still is. You can’t take your Neptune DB and go run it in Google Cloud or Azure.
- With Neo4j, you can move on prem or switch cloud providers when you want to.
- Community Support
- Amazon Neptune is built by AWS, they have a very good , in-dept and clear documentation for each of the services.
- Neo4j – Here’s a link to Neo4j’s open source repository on GitHub : https://github.com/neo4j/neo4j?ref=stackshare
- Neo4j is an open source tool with 8.7K GitHub stars and 2K GitHub forks as of March 2021.
- Neo4j Reviews report that their product is easy to learn and easy to use with plenty of resources from training materials to books.
- Monitoring
- In Amazon Neptune, you will not need to create custom indices and also since its AWS managed it can be integrated with other AWS services like Cloudwatch so that monitoring can be done easily.
- With Neo4j, we will need to build our own system for monitoring.
Conclusion
There are other competitors like GraphDB, TigerGraph and Dgraph if you want other choices.
By now, you will have a fair idea if graphdb is a good choice for your application or not. Given that you have answered a yes there, the choice between Neo4j and Amazon neptune comes down to the following factors –
- Cost of ownership –
If you don’t want to deal with data management, backups, auto-scaling, etc. That is one of the reasons why you would be choosing Amazon Neptune, otherwise if you have the bandwidth and resources to manage it yourself Neo4j would be an ideal choice. - Future proofing –
If you will not move out of AWS ever, then again Amazon Neptune would be the right choice. But If you assume you will have a hybrid cloud deployment or if you think you may move to other cloud providers then Neo4J would be an advisable choice. - Performance/support
Neo4j’s DB engine is ranked 1st among all graph database engines and provides superior performance. Also, it is widely used with great community support. So you will not have to worry about any crashes as compared to Amazon Neptune users who do report multiple issues.
Both seem to be a good fit in highly connected datasets.