Welcome back to yet another topic – GPU. If you have looked for GPU, you may well be interested in deep learning. I will walk you through each concept in GPU and the related terminologies and then we shall see later on, in this article how we are able to achieve GPU accelerated database query using two most heard of technologies namely cuDF and Blazing SQL.
In order to understand how we can achieve GPU accelerated queries, let’s understand some of the required terminologies too. Also, in case you already know, you can skip this part. But be rest assured that reading this will provide you better understanding.
Deep Learning
Deep learning is an AI function , which processes the data and creates patterns to help in decision making. It is a subset of machine learning in AI that has networks, which are basically capable of learning from data which is unstructured, untagged or unlabelled. In some use cases like detecting fraud , Money laundering etc., it can be used.
Let’s quickly understand What is GPU ? And also why would one require to implement a GPU ?
GPU
Any Data analyst, Data Scientist or a machine learning enthusiast who is working on fine tuning the model to improve performance , would have definitely hit a lag in processing data. Queries which gave processed results in minutes with a lesser training data set , now would have taken hours or sometimes weeks to execute the same query as and when the data set gets larger. So, what exactly is this GPU ? How will one use this for Deep learning projects?
Deep learning requires a lot of hardware. Some train simple deep learning models for days on their laptops (typically without GPUs) which leads to an impression that Deep Learning requires a lot of computational power to run on.
Deep Learning models can be trained faster by simply running all operations at the same time instead of running them sequentially. We can achieve this by using a GPU to train your model.
A GPU – Graphics Processing Unit is a specialised processor with dedicated memory that conventionally performs floating point operations (Mathematical) required for rendering graphics. Hence, GPU frees up CPU cycles for other jobs. A GPU is smaller than a CPU but tends to have more logical cores. Which is why – GPU is better equipped to handle this operation as it is able to execute multiple logical operations in parallel.
What factors decide whether a data science project requires GPU or not ?
This totally depends on the following things :
1. Speed
2. Reliability
3. Cost
You will need to proportion the cause of your project against the above parameters to help you judge better.
Condition -1 :
If your neural network project is a small scale, then you will be able to do it without a GPU.
Condition-2 :
If your neural network project has a truckload of high computational load, to be achieved in a short duration of time, then you should consider investing in a GPU. Which mainly targets doing multiple operations simultaneously.
Let’s move on to understanding GPUs in Databases.
GPUs in Databases
With the emergence of neural networks and deep learning which requires high computational power and speed, use of GPU in the databases have an intense need. The architecture in GPU databases is mostly a Master-slave architecture. The node farms are the masters and the database instances, receiving the subqueries, are the slaves. The slaves will now execute the subqueries and as they are on separate servers, this job will be executed in parallel and the results are sent back to the node farms which are responsible to combine all the results and send it to the client.
There is a performance increase of over 100 times when compared to traditional RDBMS, NoSQL, In-Memory databases and around 75% reduction in infrastructure costs
There are a few Commercial GPU- optimised databases. Let me make it more organised for you, i’ll divide it into 2 categories –
- GPU Databases for Analytics.
- GPU Databases for Streaming.
- GPU Databases for Analytics :
- BlazingDB: Run fast, simple SQL queries on massive datasets
- Blazegraph : ultra high-performance graph database supporting Blueprints and RDF/SPARQL APIs.
- Kinetica: Perform standard SQL queries on billions of rows in microseconds and also concurrently visualizes the results. This also helps in executing machine learning models and ingesting large amounts of streaming data.
- OmniSci: Compiles SQL queries into machine code compatible with Nvidia Corp GPUs, Intel Corp, X86, IBM Corp and Power CPUs.
- Brytlyt’s GPU-accelerated analytic database can cost-effectively query multibillion-row datasets in seconds.
- SQream: Real-time columnar database processing processes trillions of rows nearly real time.
- HeteroDB (formerly PG-Strom)
- GPU Databases for Streaming.
- FASTDATA.io for data processing and looking to significantly reduce infrastructure costs, PlasmaENGINE® can be installed in minutes with zero code changes.
- IBM Spark GPU
In this article we will see how BlazingSQL is being used along with cuDF to execute GPU accelerated database queries.
BlazingSQL
It is an open-source SQL in python . It provides a high performance distributed SQL engine in Python. Database is not needed at all. This will allow us to execute incredibly fast SQL queries on multiple data sources, like CSV, JSON, Apache ORC, Apache Parquet, GDF , Pandas and much more. BlazingSQL allows you to Extract, Transform and Load (ETL) raw data into the GPU memory as a GPU Data Frame (GDF). It is a SQL interface for cuDF.
cuDF
cuDF is a GPU-accelerated DataFrame library for loading, joining, aggregating, filtering, and manipulating data. This is mainly used for data analytics. An average data scientist spends 90% of their time in ETL as opposed to training their models.
- cuDF is a python library for manipulating GPU dataFrames following the pandas API.
- Python interface to CUDA C++ dataframe library (libcudf).
- Allows to create GPU dataframes from Numpy arrays, Pandas DataFrames, and PyArrow tables.
- JIT compilation of user defined functions(UDFs) using Numba.
Lets see How we implement the GPU database accelerated queries using Blazing SQL and cuDF , refer the following image :
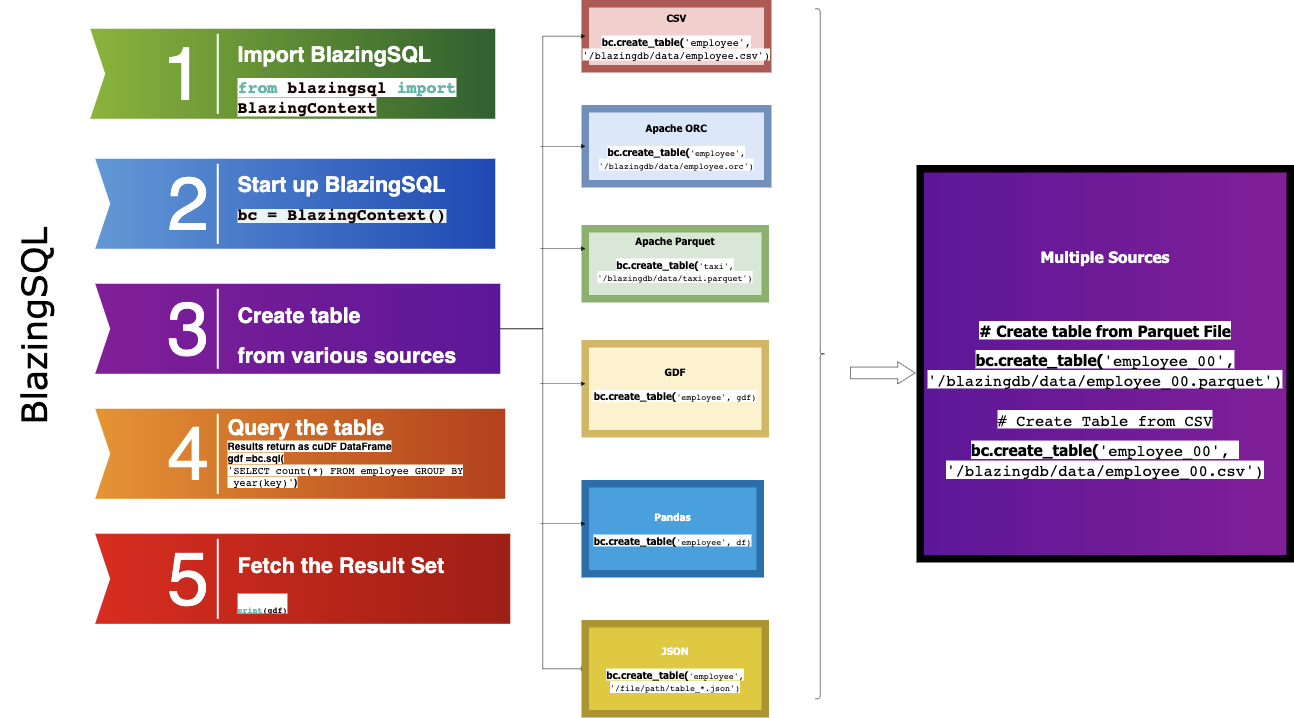
There are two libraries specific to data manipulation:
- BlazingSQL: SQL commands on a cudf.DataFrame
- cuDF: pandas-like commands on a cudf.DataFrame
BlazingSQL is a SQL engine built on top of cuDF, the cudf.DataFrame package. This means you can easily chain together SQL queries in Python and the RAPIDS ecosystem to build complex and scalable data pipelines for machine learning, graph analytics, and more.
Furthers let’s also see how cuDF performs over Pandas, Here I ran a simple code and these are the output to analyse the same :
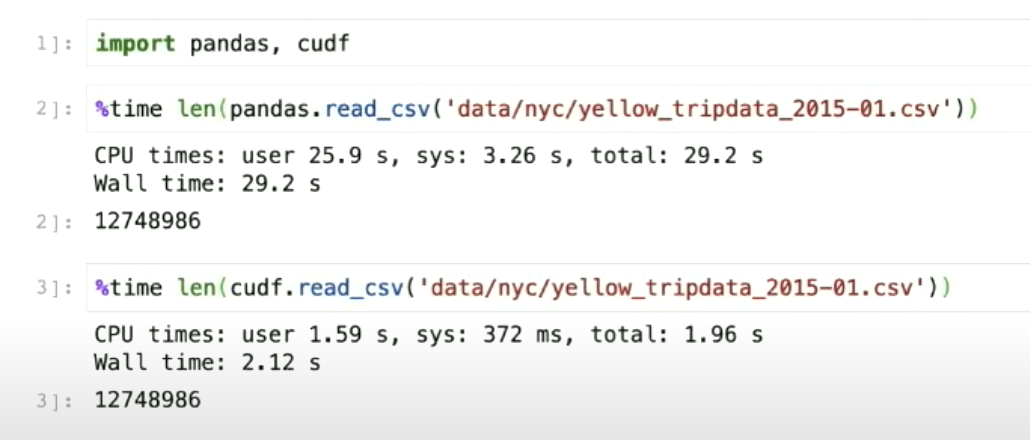
We can see here cuDF performed better with 10x speedup capability. Key is to GPU-accelerate both parsing and decompression wherever possible.
Let’s benchmark Pandas vs cuDF using the datasets of 10M rows and 100M rows both having 2 columns each.
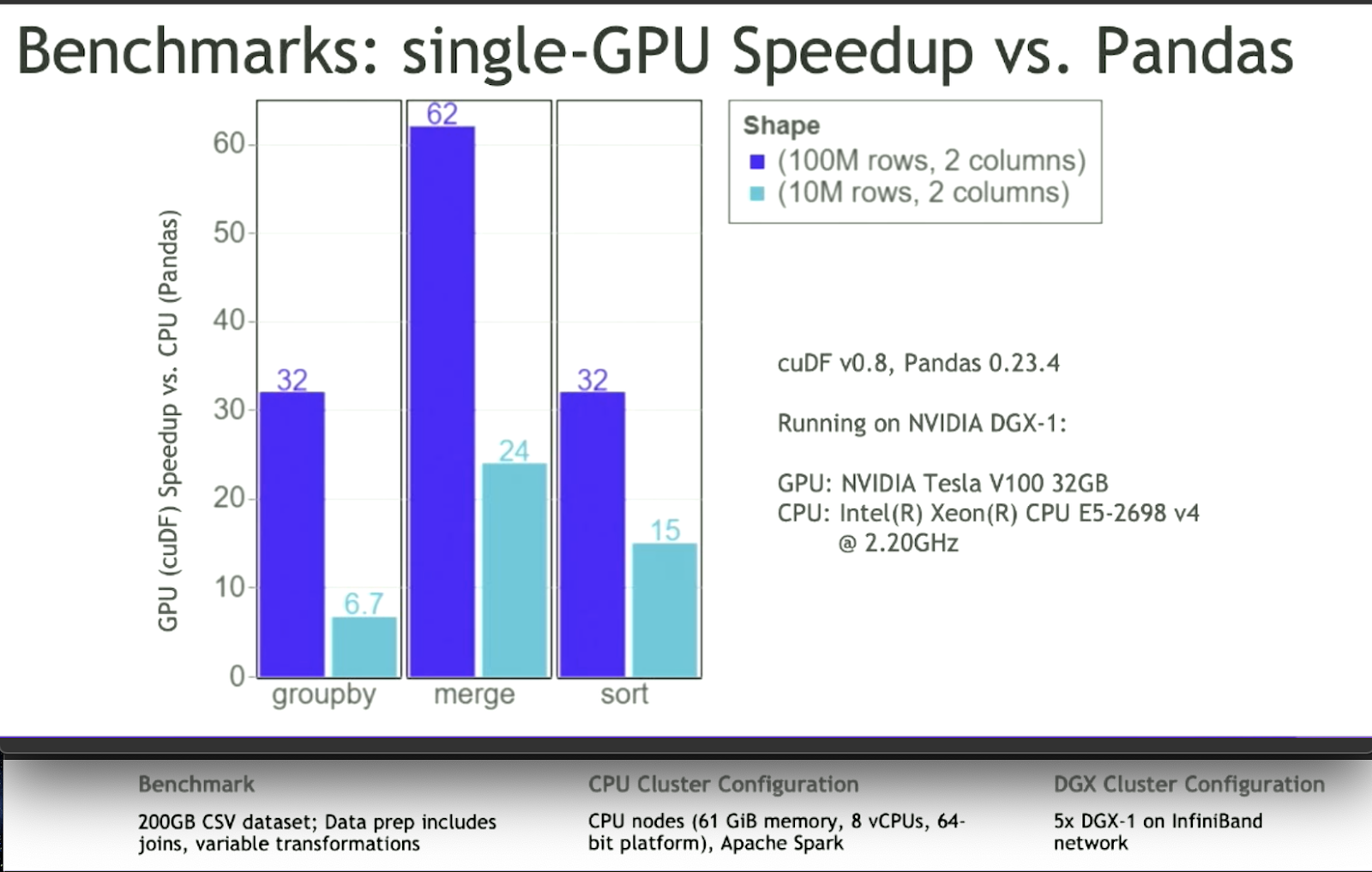
It’s evident that cuDF performs better for GPU accelerated database queries.
Conclusion
So, if you are a Data scientist or a machine learning enthusiast and are looking forward to implement GPU accelerated database queries, and find yourself in a dilemma if this fits your use case, then try answering the following-
- What is the size of the data that needs to be computed ?
- What is the computational power you will require to address your needs ?
- What proportion of speed, reliability and cost you are planning to put for this data project ?
Based on these questions, if you have extremely large amounts of data which will need significant computational power, then chances are that you will most definitely require a GPU.