
Envision this : like XML, but smaller and faster in design.
What are Protocol buffers ?
Protocol Buffers are language-independent and platform-independent, open source library, used for serialising structured data. In other words, it is a way of encoding structured data in an efficient yet extensible format.
When we have to send the data, we do think about what protocol we need to use and also what should the structure of the data be. There are different types of data transfer , we will need to consider the size and efficiency of data as well, later we go about thinking what the requesting server is using this data for.
You would be familiar with JSON and XML data formats, where JSON- javascript object notation and Xml is extensible markup language. The main advantage of these two languages is that it is readable and easy to understand.
Lets us see a simple example of how the data is represented in JSON,

This same object can be represented in XML as follows :

While XML is more relevant for the front end use, JSON is the preferred way in the backend.
Let’s move onto ProtoBufs, also called ProtocolBuffers , this is Googles creation in 2008. Protocol Buffers are widely used at Google for storing and interchanging all kinds of structured information. The method serves as a basis for a custom remote procedure call (RPC) system that is used for nearly all inter-machine communication at Google.
Protocol buffers were actually created with XML in mind in terms of speed and efficiency. Which google wanted to create for themselves which will be faster than normal standards of XML. And also ProtoBufs are language-independent and platform independent as well.
How do ProtoBufs work ?
Uses a determined schema to encode and decode – this adds a layer of security. And it can be compiled into many different languages.
JSON is not structured data, whereas protocol buffers are structured data , Lets consider the following structure to understand ProtoBufs better,

This is a schema representing employee details
How do we represent this as an array of employees in ProtoBufs ?
The beauty of the protocol buffer is , it is language-independent, lets see how to create an array of employeeDetails ,

A proto file is a schema definition about your messages and structured data. This proto file will need to be converted to any target language file. Google has built a compiler called protoC, to this you will need to feed it, what language you want the output to be, and it will output that equivalent language. If you give javascript, the protoC will give you a javascript equivalent file, in case you give it a python, it will give you a python file with the same schema. That is why it is language neutral.
Checkout their official release in https://github.com/protocolbuffers/protobuf/releases. Using this , you will need to find the protoC , the compiler for your OS, here it has nothing to do with the language.Once you have downloaded the protoC, you will need to extract it, here you will find the protoc executor.
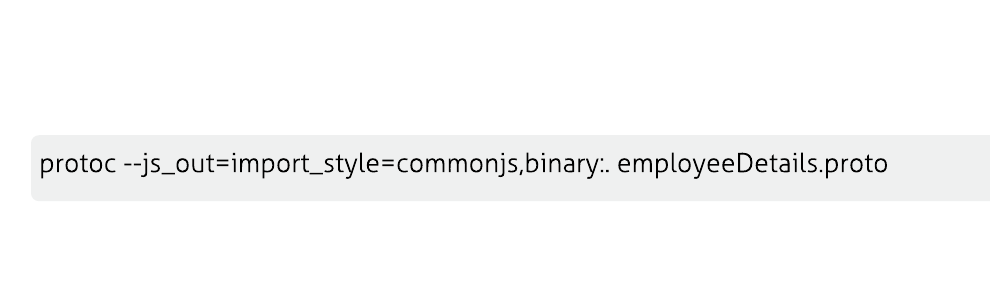
Here js_out is used to get the javascript equivalent of the protobuf. The employeeDetails.proto is our schema definition file for the proto. On execution in the protoc compiler, using the above command, this will throw out a employeeDetails_pb.js file.
The binary generated is very much less in size when compared to the JSON file.
Conclusion:
Protocol buffer is a winner for small messages where the ProtoBuf size is as small as 16% of the gzipped json size. But protocol buffers forces us to have a structured schema, this would be a barrier to entry for some use cases. This has more involved process for small schema. Have to make sure to update compiled boilerplate code. However its language-neutrality is definitely the icing on the cake.